Kafka is an open-source data storage system for real-time data with a very high frequency that is needs to be written to a database in real-time. It serves as an extra layer between the database and the client which is sending the data.
Why is there a need for Kafka?
Let us suppose a system where a lot of real time data is to be sent to a database for analytics purpose. For example, consider Uber sending data of the driver reaching towards the customer in real time. If we take all the drivers a particular time globally then this data can be very huge. Sending these bits of data to the database every second or every half a second or at a frequency even higher than that would cause the database to crash because traditional databases have very low throughput, and they will not be able to handle this type of data. To solve this purpose, Kafka comes into the picture. Kafka serves as a reserve to contain all this data in real-time due to its very high throughput and send this data to the services for analytics purpose.
How is Kafka used?
Kafka is used as an extra layer between the client and the backend infrastructure of the application.
Below is a high-level overview of how Kafka works with the application.
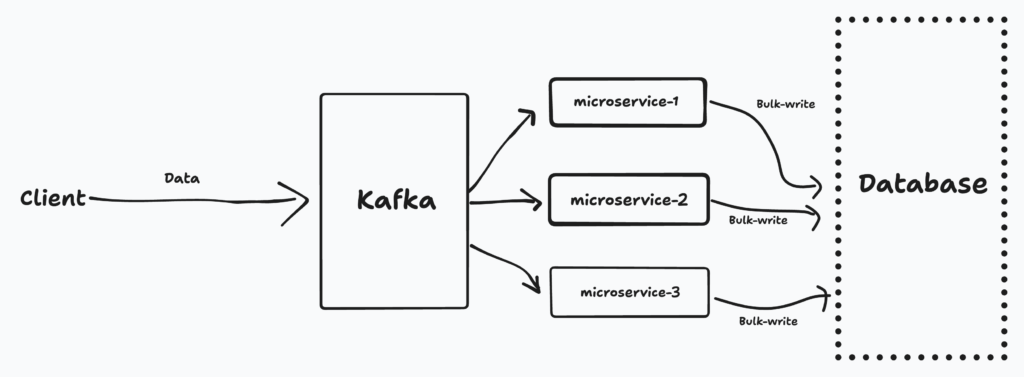
Seeing, the above diagram, we can understand the flow of the application. When the client sends the real-time data, the Kafka reservoir can contain that data in itself. This data can be then sent to the individual microservices for different scientific or business calculations. The microservice can then use a bulk write operation to the database of the application. This whole process is done because Kafka having a high throughput capacity does not have the high store capacity like the traditional database. We use the pros and cons of both Kafka and traditional database to achieve this functionality.